我想要做一个能够很方便地用于目标检测的数据集,目前是调用了Qwen2.5 VL的API来进行一个检测,能够对每张图片输出零个,一个或者多个json格式的检测框,我想要保存成标准的YOLO或者COCO格式,方便之后使用YOLO或者其他算法进行目标检测,你有什么建议吗
结合你的需求,以下是构建YOLO/COCO格式数据集的系统化建议(附代码框架和注意事项):
一、核心步骤建议
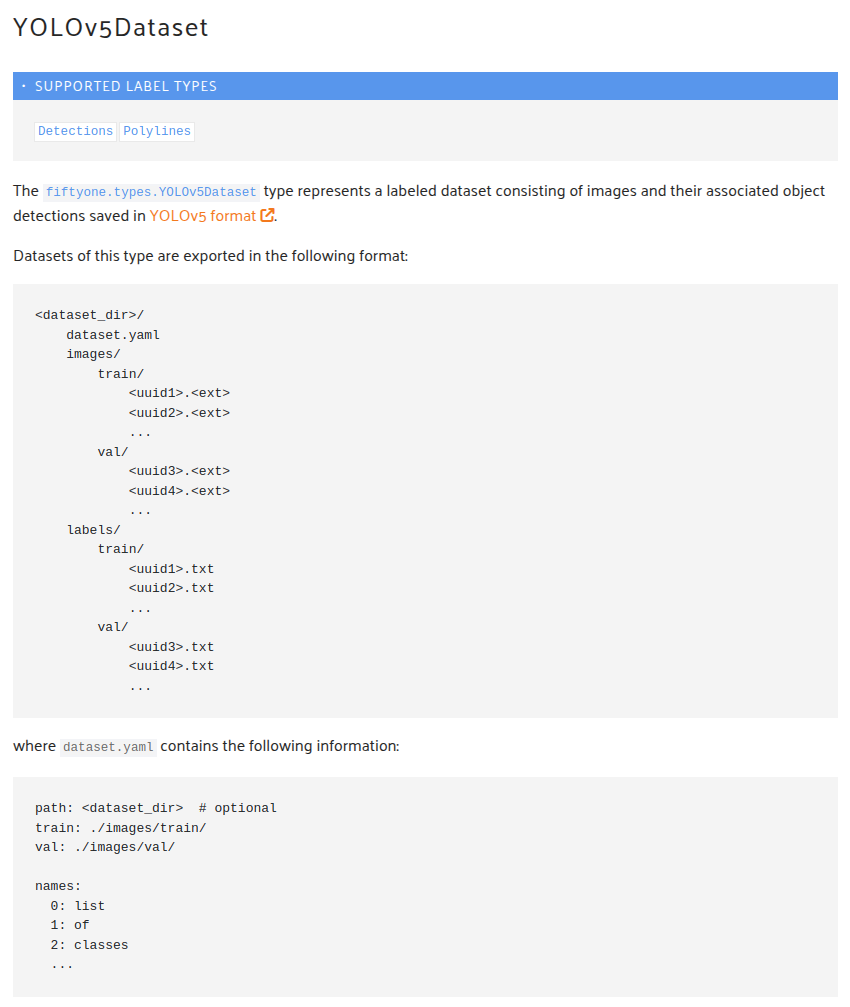
- 统一数据目录结构(参考)
1
2
3
4
5
6
7
8
9
10
| dataset/
├── images/
│ ├── train/
│ └── val/
├── labels_yolo/
│ ├── train/
│ └── val/
└── annotations/
├── train.json
└── val.json
|
- 类别映射文件(必须)
创建classes.txt,每行一个类别:
- YOLO V5格式转换(核心逻辑参考)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import json
from PIL import Image
def qwen_to_yolo(api_result, img_path, save_dir):
img = Image.open(img_path)
img_w, img_h = img.size
yolo_lines = []
for box in api_result['boxes']:
cls_id = class_map[box['class']]
x_center = (box['xmin'] + box['xmax'])/2 / img_w
y_center = (box['ymin'] + box['ymax'])/2 / img_h
width = (box['xmax'] - box['xmin']) / img_w
height = (box['ymax'] - box['ymin']) / img_h
yolo_lines.append(f"{cls_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
txt_path = os.path.join(save_dir, os.path.splitext(os.path.basename(img_path)) + '.txt')
with open(txt_path, 'w') as f:
f.write('\n'.join(yolo_lines))
|
- COCO格式转换(参考)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| coco_template = {
"images": [],
"annotations": [],
"categories": []
}
for idx, cls in enumerate(classes):
coco_template['categories'].append({
"id": idx+1,
"name": cls,
"supercategory": "none"
})
image_id = 0
annotation_id = 0
for img_path in all_images:
img = Image.open(img_path)
coco_template['images'].append({
"id": image_id,
"file_name": os.path.basename(img_path),
"width": img.width,
"height": img.height
})
for box in api_results[img_path]:
coco_template['annotations'].append({
"id": annotation_id,
"image_id": image_id,
"category_id": class_map[box['class']] + 1,
"bbox": [box['xmin'], box['ymin'], box['xmax']-box['xmin'], box['ymax']-box['ymin']],
"area": (box['xmax']-box['xmin'])*(box['ymax']-box['ymin']),
"iscrowd": 0
})
annotation_id += 1
image_id += 1
with open('annotations/train.json', 'w') as f:
json.dump(coco_template, f)
|
二、关键注意事项
- 坐标归一化:YOLO格式需要将坐标除以图片宽高(0-1范围),COCO使用绝对像素值
- ID起始值:YOLO类别从0开始,COCO类别建议从1开始(兼容性更好)
- 数据拆分:建议按8:1:1划分train/val/test,可使用
sklearn.model_selection.train_test_split
- 验证工具:
- YOLO格式:使用
Ultralytics的yolo val命令验证数据加载
- COCO格式:使用
pycocotools验证json合法性
三、推荐工具链
格式转换:使用Ultralytics官方工具convert_coco()
可视化验证:
1
2
| yolo task=detect mode=val data=coco.yaml
yolo train data=yolo.yaml
|
自动化脚本:参考MMYOLO的转换工具
建议先处理小样本(如50张图片)验证整个流程,再扩展到全量数据。如果遇到API返回坐标格式问题,可使用OpenCV的cv2.warpAffine进行坐标转换适配。