隐式三维建图

在三维重建和场景理解方面具有很多特性和优势,嘉宾在SLAM,三维重建,表征等方面都有很多的paper









iMap使用隐式表征的实时重建系统

一个场景的计算资源,把物体都框出来,让资源专注到物体上
系统可以将每个物体分割并且重建出来,多个物体可以被并行地优化
系统没有3D先验,之前有别的kiloNerf是有先验的
每个nerf占用的空间很小,可以并行地优化多个物体,这种优化可以比单一的MLP更高效地建模整个场景






很多模型都是一个视角的示图输入,但是这个模型可以随意地拍摄任意张图片,然后传入去生成图像











将任意的没有pose的图片输入,就可以生成点云这样子,第一个前向过去,很快
得到物体级别的表征,任意角度的输入,可以恢复真实尺度,可以得到更完整的mesh,将真实世界的观测和重建,做online的 policy训练,将policy直接部署到真实世界当中

和世界模型

未来是不是生成式模型,生成式模型能够带来足够的重建,帮助现有的重建和生成,因为现在的SLAM系统都是能够将观测的部分给重建出来,不能像人类一样将其背面的内容给重建出来
提出的方法可以直接建立STL格式的图档吗,STL需要更精细的mesh网格,但是现在有一个公司能做到,3D重建的结果
提出来的方法可以在线的优化和重建,在家了foundation model和difussion model之后,还能继续重建吗
目前还不太行




理想的地图表示
点云地图




训练一个神经网络去fit SDF,省内存,连续可微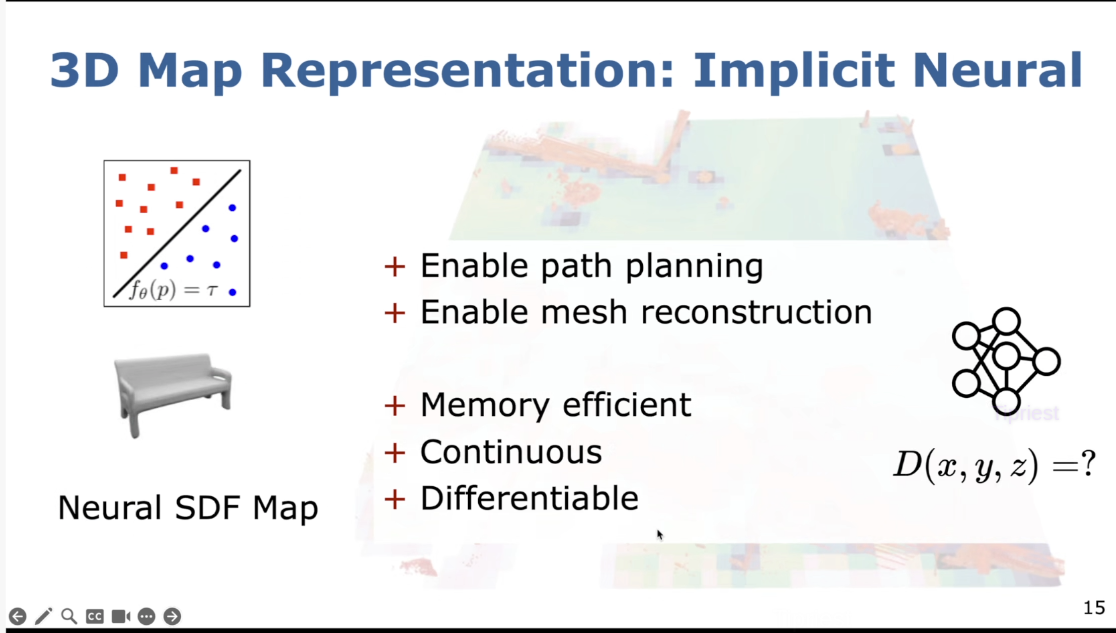


神经网络做的是一个回归任务

单一的神经网络没有办法fit罗马
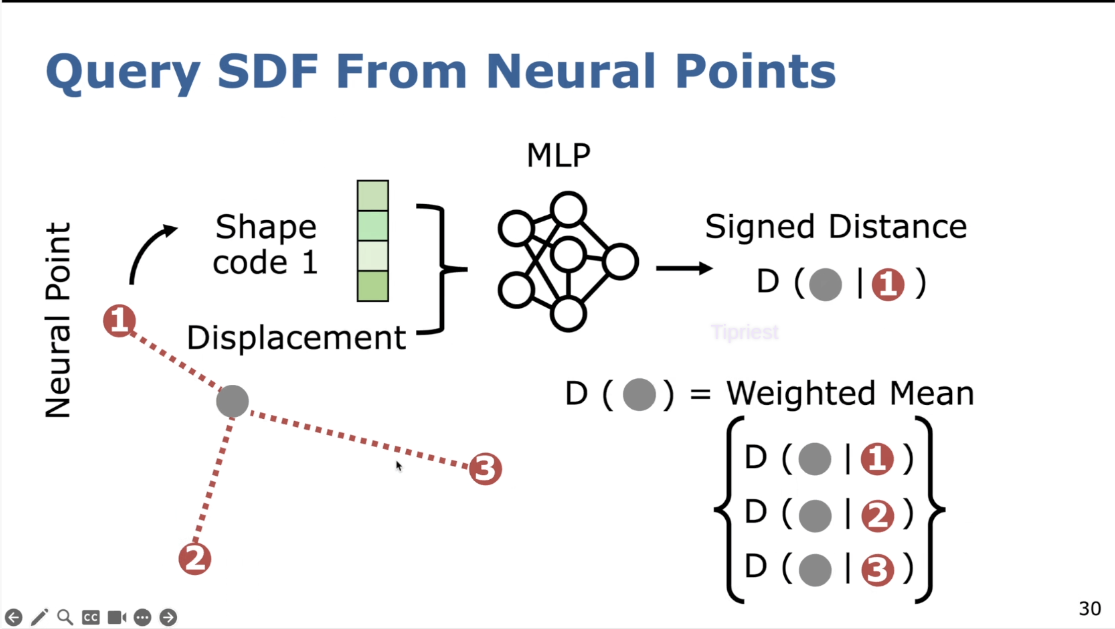








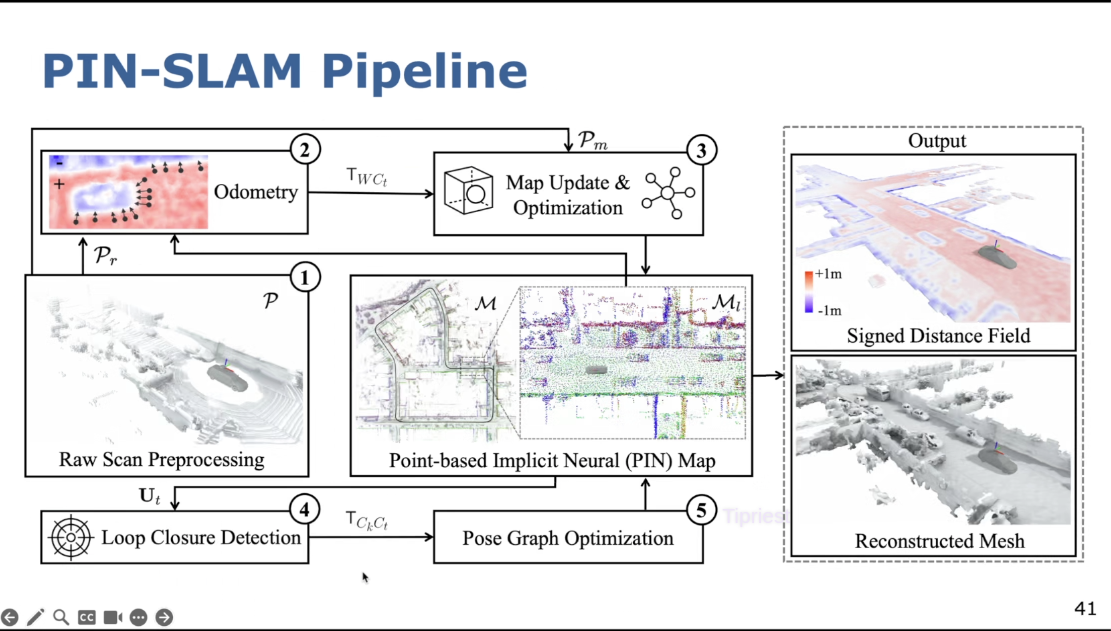



通过回环可以让神经点云一致
在Apollo数据集上,32km 2.2m RSME


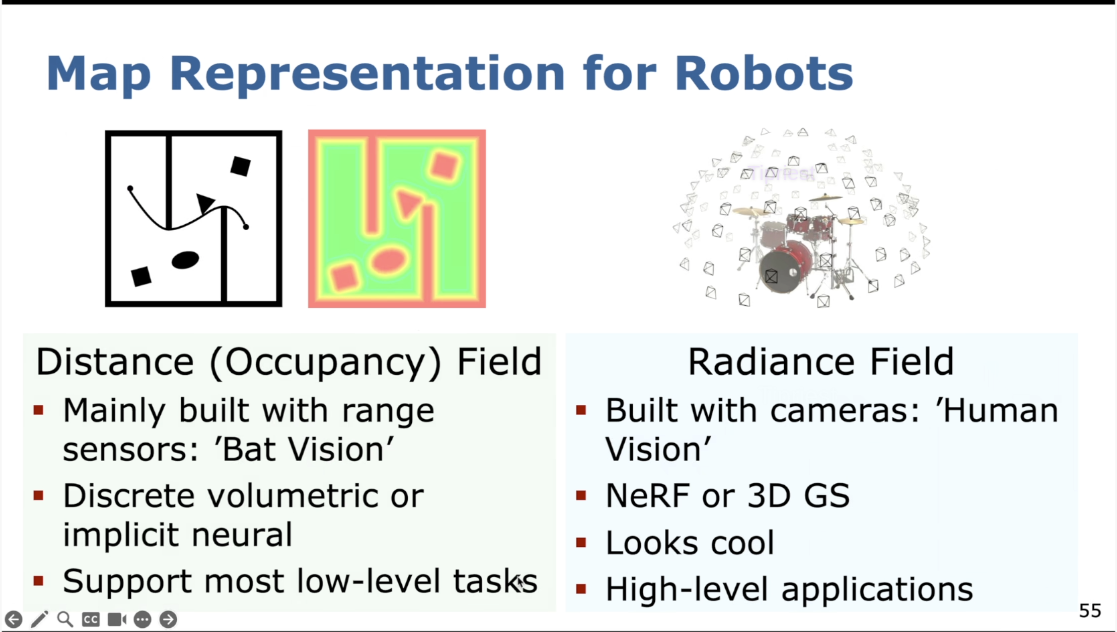








GS的问题,在几何上可能会有一些cheating












SLAM算法现在不是实时的,既可以做rendering,同时做一个mesh的表面重建







VLA加入一个场景的memory,提高VLA的效果
隐式表达省内存,但是消耗算力,这个怎么考虑?


更关注室内场景,不是很偏重Nerf或者GS






















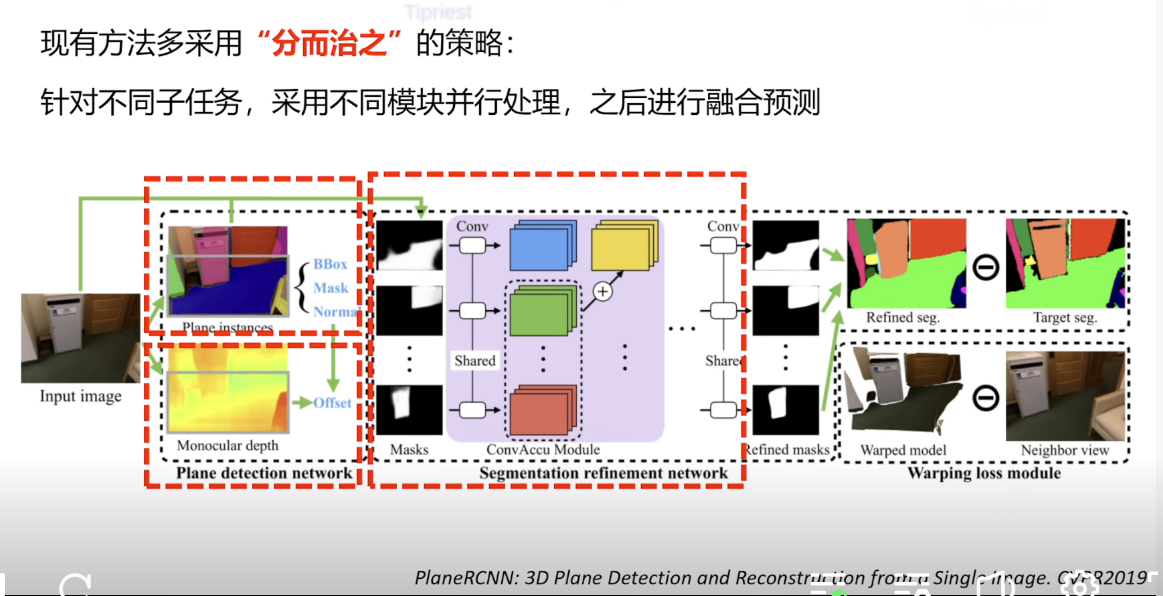








两个图片之间的相机位姿?
两个图片的一个平面如何进行关联?






总结和展望:结构化几何表征




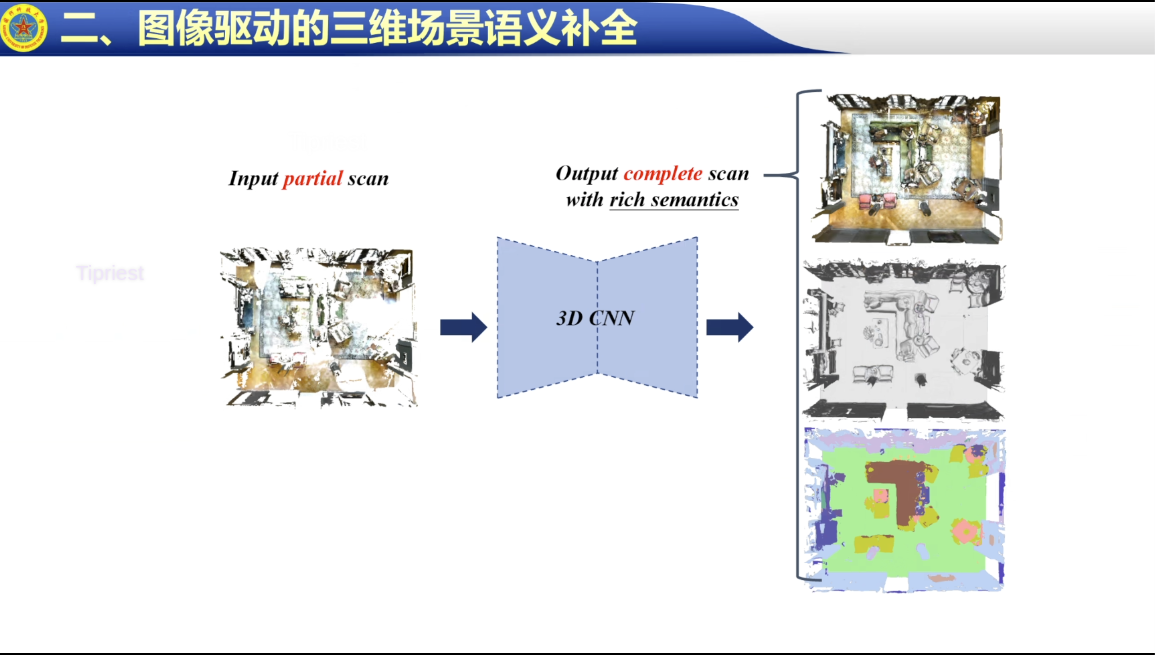
补全和生成有什么区别,用difussion来做可行吗
补全来做就是一种无中生有的感觉
difussion可能是用在很多更general的task上
3D的真值的问题,3D的真值是怎么得到的,深度图像的ESDF,做ransank
数据集的做法是将比较差的平面去掉,留下好的结果
圆桌讨论
对隐式的三维表征还不是特别一样
Nerf是,但是GS是不是?
三维的隐式表征的定义是什么?
孔:
未来的趋势,大模型提供先验,表征提供pipeline master slam,有一个很好的先验给一个很强的初始化,我们的报告中的nerf都是没有先验的从random初始化的根据观测进行重建的过程,需要一个很好的先验模型,先验还是很重要,结合大模型
潘越; 纯forward的版本,不需要先验啥的,纯forawrd的版本的质量上比起做优化还是会差一些,能增量式做一些construction还是比较少
结合大模型,推理其实还好,VGGT,100张图的推理只有几秒钟,不管是隐式还是显式的点云的表征,未来可能都是会有一些比较好的初始化,还是会有后面的一些优化存在,但是现在的feed forward的还是不能长期优化,还是要有后端BA,很重要,模型会给你一个比较好的初始值,但是模型后面的后端优化还是很重要
和下游的导航和大模型结合的问题,未来的三维重建和下游的大模型,VLM,如何结合,有哪些比较好的结合点?
3D视觉就是给机器人解决方案,但是很多工作train一个VLA模型就很好,不需要一个中间的3D表达,但3D视觉更像是一个中间的grounding,假设你的系统是能够实现一个3D操作,但是3D视觉能够实现中间的监督和验证部分,直接端到端短期由于数据部分,但是作为一个组件,2D和3D视觉能够比较好的作为一个pipeline,接到下游的导航这样子
隐式的优势是他更容易结合网络,用神经网络的方式调参
把隐式的表征和导航/操作来结合
